An open toolkit for composable, automatic, and scalable learning

Composable
To quickly assemble your applications

Automatic
To automatically tune your models

Scalable
To efficiently train your large models
For machine learning in the real world
Learn more
Projects
Examples
3
Scale across GPUs with Minimal Coding
A novel TensorFlow training engine for distributed deep learning
CASL Updates
Latest updates and news about CASL

Building a Question Answering System Part 3: Answer Extraction
Building a Question Answering System Part 2: Document Retrieval

Introducing Tuun, an Open Source System for Hyperparameter Tuning via Uncertainty Modeling
Building a Q&A System Part 1: Query Understanding in 18 lines
Improving AI models through Automatic Data Augmentation using Tuun


Optimizing Elastic Deep Learning in GPU Clusters with AdaptDL for PyTorch
AdaptDL is now featured on the PyTorch ecosystem!
Forte: Building Modular and Re-purposable NLP Pipelines
We have integrated AdaptDL with NNI for cost-effective hyperparameter tuning


AdaptDL and AutoDist Tutorial (AAAI 2021)
Simplifying and Automating Parallel Machine Learning via a Programmable and Composable Parallel ML System

Texar and Forte Tutorial
(KDD 2020)
(KDD 2020)
Learning from All Types of Experiences: A Unifying Machine Learning Perspective
Introducing Texar-PyTorch:
An ML Library Integrating the Best of TensorFlow into PyTorch
Partners





Research and Technology
OSDI 2022
Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning
AAAI 2021
BANANAS: Bayesian Optimization with Neural Architectures for Neural Architecture Search
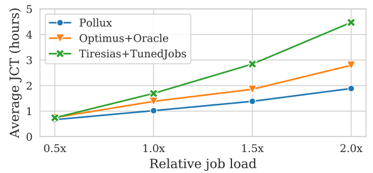
Pollux: Co-adaptive Cluster Scheduling for Goodput-Optimized Deep Learning
AAAI 2020 Tutorial
Tutorial: Modularizing Natural Language Processing
Journal of Machine Learning Research (JMLR), 2020
Tuning Hyperparameters without Grad Students: Scalable and Robust Bayesian Optimisation with Dragonfly
NeurIPS 2020
A Study on Encodings for Neural Architecture Search
EMNLP 2020
A data-centric framework for composable NLP workflows
AAAI 2021
On Trustworthiness of ML Algorithms -- and implications in AI-driven healthcare
ASYML
Machine Learning as Machine Assembly